
SeqAn - Sequential data distribution analyse
Základní popis vlastností programu
Autor Karel Matějka - IDS, Praha
Úvod
Při hodnocení výsledků chromatografie / elektroforézy gelové / na tenké vrstvě / papírové a podobných metod jsou k dispozici media, kde u série několika vzorků (relativně malého počtu) je sledována poloha vzorku (jeho části) po jeho unášení v médiu. Měřitelná je tak vlastně rychlost pohybu vzorku. Lze předpokládat, že logaritmus těchto rychlostí má pro vzorky jednoho druhu normální rozdělení. Vzhledem k malému počtu vzorků je obtížné běžnými statistickými postupy rozlišovat vzorky různého charakteru - z malého počtu hodnot většinou nelze porovnat odchylky rozdělení skutečně naměřených hodnot od očekávaného normálního rozdělení a tak stanovit, že některé vzorky jsou odlišného druhu. Vhodnější je vzestupně seřadit naměřené hodnoty a analyzovat jejich diference. Na základě použitého kriteria lze stanovit, které diference jsou již tak velké, že s pravděpodobností přesahující určitou nastavenou hladinu, oddělují hodnoty náležející do dvou různých rozdělení (odpovídají vzorkům jiného charakteru).
Předpokládejme, že máme skupinu hodnot Xi (i = 0 ... n-1) [představujících proměnné v programu označované
Rf, případně jejich logaritmy] představujících výběr z normálního rozdělení N(x,sx2) a nechť je tento výběr uspořádaný vzestupně (Xi<=Xi+1).Potom můžeme říci, že nějaká jiná hodnota XK není z téhož normálního rozdělení N(x,sx2) s pravděpodobností větší než P (s chybou menší nežli 1-P) tehdy, když XK-Xn > DP nebo X0-XK > DP, kde DP je určitá kritická hodnota.
Testování lze tak provést následujícím způsobem:
Testování tímto způsobem provádí program SeqAn.
Tabulky a grafy kritických hodnot
Kritické hodnoty DP(n) byly odhadnuty pro rozdíly uspořádaných hodnot z normálního rozdělení N(0,1) na základě generování velkého počtu náhodných výběrů ze zmíněného rozdělení a byly tabelovány (n značí počet analyzovaných hodnot). Kritické hodnoty pro rozdělení N(x,sx2) je možno vypočítat jako sx–násobek tabelovaných hodnot.
|
P |
||
n |
0,50 |
0,95 |
0,99 |
2 |
0,9602 |
2,7710 |
3,6191 |
3 |
0,6871 |
2,1720 |
2,9086 |
4 |
0,5469 |
1,8202 |
2,4865 |
5 |
0,4478 |
1,5929 |
2,2076 |
6 |
0,3800 |
1,4094 |
2,0326 |
7 |
0,3338 |
1,2830 |
1,8758 |
8 |
0,2949 |
1,1809 |
1,7579 |
9 |
0,2640 |
1,0889 |
1,6557 |
10 |
0,2393 |
1,0017 |
1,5637 |
Příslušné kritické hodnoty jsou zobrazeno rovněž na následujícím grafu
Program SeqAn provádí odhady (přibližné výpočty) těchto kritických hodnot a pro opětovné použití je zapisuje do vlastní tabulky. Umožňuje zobrazení okna pro výpočet odhadů kritických hodnot diferencí. Zde lze vypočítat i kritické hodnoty pro diference mezi seřazenými hodnotami výběru z některých dalších typů rozdělení (vedle normálního též pravidelné, chi-kvadrát, t-rozdělení a F-rozdělení).
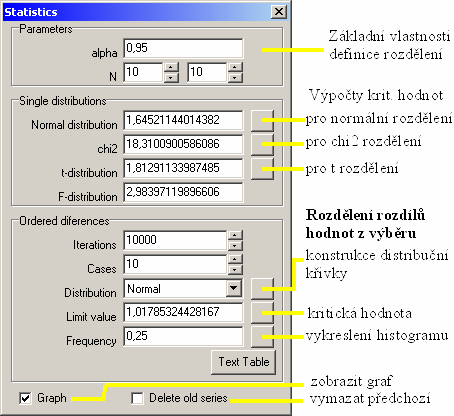
V horní části okna jsou definovány základní vlastnosti rozdělení a používaná kritická hodnota. Ve střední části okna je možné počítat kritické hodnoty pro základní používaná rozdělení.
Rozdělení diferencí mezi seřezenými hodnotami náhodného výběru je možné počítat ve spodní části okna. Zde je potřebné vybrat především typ základního rozdělení (program SeqAn používá pro vlastní analýzy normální rozdělení) a velikost výběrového souboru. Pro vlastní výpočet je potřebné uvést i počet iterací z nichž se distribuční funkce diferencí počítá (součin obou uvedených hodnot by většinou neměl přesahovat cca 100 000, protože jinak se proces výpočtu může stávat příliš náročný, nízké hodnoty však vedou k nepřesnostem).
Hlavní okno programu
Zobrazení dat
Existují dvě základní možnosti zobrazení dat:

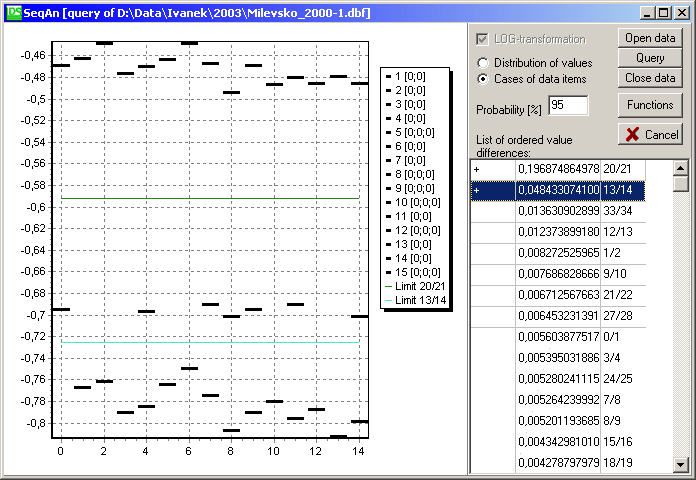
Tabulka diferencí, hranice tříd dat
Sestupně uspořádané diference jsou vypsány též numericky v pravé spodní části okna. Prvý sloupec označuje definovanou hranici třídy hodnot, případně její statistickou průkaznost, ve druhém sloupci je uvedena velikost diference a v posledním sloupci indexy hodnot, mezi nimiž je diference vypočítána.
Dvojitým kliknutím na jednotlivých řádcích je zde možné přidávat hranice pro oddělení tříd hodnot. Tyto hranice jsou současně vykreslovány v grafu. Hranice je označena znakem +, který je po výpočtu statistik nahražen symboly pro významnost hranice:
x x |
hranice je statisticky průkazná vzhledem k rozdělení hodnot spodní i horní třídy |
o o |
statisticky neprůkazná hranice |
x o |
hranice je statisticky průkazná zvhledem k rozdělení hodnot spodní třídy, ale neprůkazná vzhledem k rozdělení hodnot horní třídy |
o x |
opačný případ vzhledem k předchozímu |
x _ |
hranice je statisticky průkazná zvhledem k rozdělení hodnot spodní třídy, pro nedostatek hodnot v hodní třídě ji nelze testovat |
_ x |
opačný případ vzhledem k předchozímu |
_ _ |
hranici nelze testovat ani proti spodní třídě hodnot, ani proti horní třídě (obě mají nedostatek hodnot pro výpočet) |
Další kombinace o _ nebo _ o jsou zřejmého významu.
Výpočet základních statistik
Vypočte základní statistiky definovaných datových tříd a seznam diferencí, které přesahují příslušné kritické hodnoty. Výsledky jsou shrnuty v samostatném okně.
Ke každé třídě hodnot je zde uveden následující údaj (obdobná tabulka je i součástí tištěného výstupu):
Class |
označení třídy (první třída je vždy označena A, dále B, ...) |
First |
index první hodnoty dané třídy (pořadové číslo hodnoty ve vzestupně uspořádaném seznamu hodnot, první hodnota je vždy označena 0) |
Last |
index poslední hodnoty dané třídy |
AVG |
aritmetický průměr všech hodnot dané třídy |
STD |
odhad směrodatné odchylky hodnot patřících do dané třídy (je porovnatelný i pro třídy s různým počtem prvků) |
CritVal |
vypočítaná kritická hodnota pro rozdíl mezi dvěma hodnotama náležejícíma do dané třídy: pokud je vypočítaná diference mezi dvěma hodnotama větší, pak je odůvodněné rozdělení třídy na dvě položením nové hranice mezi tyto hodnoty |
Important |
označení diferencí, které jsou větší než uvedená kritická hodnota |
Používané datové soubory
Přímé použití dat zapsaných v textových souborech
Možné je načítat data z textových souborů, kde položky jsou odděleny středníkem (standardně s extension CSV). V každém souboru je umístěna jedna zpracovávaná datová série.
Data z databázové tabulky formátu DBF
Data lze načítat z databázové tabulky formátu dBase-FoxPro (DBF) pomocí SQL dotazu SELECT. Klasická tabulka formátu DBF musí mít atributy
ID (celočíselná hodnota jako identifikace pozice vzorku), Start (počíteční poloha vzorku), Rf1 (případně Rf2 až Rf[n] - dosažené polohy jednotlivých složek vzorku). Dále může obsahovat atribut Factor (pro vyrovnání dat při srovnávání více datových sérií), Clas pro zápis výsledků zpracování, Inc1 (až Inc[n]) pro logickou hodnotu o zařazení příslušné Rf hodnoty do zpracování a libovolný počet dalších údajů sloužících k identifikaci datových sérií a jednotlivých vzorků.Importovaná textová data
Importovat lze textová data odělované libovolným separátorem nebo data s pevnou šířkou sloupce, přičemž speciálním případem je import dat z programu ImageMaster.
Další funkce programu
Regrese dat
Rychlost pohybu vzorku může být závislá na poloze vzorku na médiu (to je časté v případě elektroforézy, kde intensita elektrického pole může být závislá na místě). Proto lze provést vyrovnání dat podle polynomu vybraného stupně.
Porovnání více datových sérií
Dvě nebo více datových sérií (například vzorky na dvou gelech) nelze přímo porovnávat - Rf hodnoty (nebo lépe jejich logaritmy) si nemusí přímo odpovídat přes to, že se jedná o totožné vzorky. Pokud je známo, že hodnoty určitých tříd si odpovídají (například třída 1 na gelu A odpovídá třídě 2 na gelu B), je možné provést vyrovnání na průměr těchto tříd (postupně pro každý gel zvlášť) a poté obě série porovnávat společně.
Uložení výsledků klasifikace
Při výpočtu statistik je každá hodnota zařazena do jedné třídy hodnot (třídy jsou značeny velkými písmeny postupně A, B, ...). Funkce umožní zapsat zjištěnou kombinaci všech tříd hodnot pro každý vzorek do databáze.
Změna vlastností grafu
Ve standarním dialogovém okně je možné editovat základní vlastnosti grafu a zobrazených datových sérií. Vlastnosti datové série je možné editovat po jejím vybrání ze seznamu a jejím označení pravým tlačítkem myši - objeví se menu se základními vlastnostmi, které je možné změnit.
Uložení grafu do souboru
Vytvořený graf je možné uložit jako specifikovaný grafický soubor.
Tisk výsledků
Vytiskne sestavu analýzy dat s grafem a základními statistikami definovaných tříd.
Propojení s dalšími programy
Program SeqAn je možné propojit s jinými programy - může totiž pracovat jako COM server. Toho bylo využito pro zapojení programu do informačního systému budovaného pro klienta.
Zpět na hlavní stránku IDS
© Karel Matějka - IDS (2003)