Viz též: Menu programu, Používané soubory, Programy v aplikačním balíku
Tento program dokáže klasifikovat objekty metodami jako programový balík PC-ORD (McCune et Grace 2002). Pro výpočet jsou užívána data exportovaná programem DBreleve pro systém PC-ORD ("work-file", soubor s koncovkou wrk). Jedná se o jednoduchý program ovládaný příkazovým řádkem. Výstup je prováděn do textového souboru se jménem shodným, jako je jméno souboru dat, ale s koncovkou out ("output-file"). Je možno klasifikovat objekty rovněž na základě matice nepodobnosti uložené v samostatném souboru.
Výběr míry nepodobnosti (distance):
EUCLIDEAN DISTANCE - Euklidovská vzdálenost.
SQUARED EUCLIDEAN - Čtverec euklidovské vzdálenosti.
2W/(A+B) DISTANCE - Doplněk Sörensenova koeficientu podobnosti. Distance je počítána na základě dat presence/absence.
Libovolná míra nepodobnosti uložená v samostatném textovém souboru v podobě podobnostní matice. Viz příklad v instalačním adresáři programu (./example/dist.txt). Takovou podobností matici lze konstruovat například v programu CorrelDist ve formě korelačních vzdáleností (Matějka, 2017).
Výběr aglomerační procedury:
NEAREST NEIGHBOR (single linkage) - Metoda nejbližšího souseda.
FARTHEST NEIGHBOR (complete linkage) - Metoda nejvzdálenějšího souseda.
MEDIAN (také WPGMC) - Mediánová metoda.
GROUP AVERAGE (také UPGMA - unweighted pait-group average method) - Metoda průměrné vzdálenosti.
CENTROID - Metoda těžiště.
WARD`S METHOD - Wardova metoda (Ward 1963).
FLEXIBLE BETA
MCQUITTY`S METHOD - (McQuitty 1966).
Metoda hierarchické aglomerativní klasifikace sekvenčně uspořádaných vzorků byla popsána v publikaci Matějka (1993). Tento program je psán obdobným způsobem, jako program předcházející. Užívá též data formátu work-file (pozor: fytocenologické snímky - vzorky musí být v souboru sekvenčně uspořádány). Pro výpočet je možno užít následující koeficienty
- postupné počítání podobností
1 - average constancy of species (S): Průměrná konstance je počítána na základě dat presence/absence
2 - complement of sum of species variance (Sq): Výpočet vyžaduje standardizaci dat tak, aby suma presencí všech druhů byla rovna 1
- přímý výpočet matice podobnosti
4 - minimum of Sörensen`s similarity coefficient: výpočet na základě dat presence/absence
5 - minimum of Jaccard`s similarity coefficient: výpočet na základě dat presence/absence
6 - complement of maximum Euclidean distance
Výstup je opět do souboru *.out. Takový soubor může vypadat následovně:
************************************************************
The hierarchical semi-cluster analysis (HSCA)
author Karel Matějka - IDS
************************************************************
name of the data and the course of HSCA:
CHOICE OF THE METHOD:
2 - complement of sum of species variance (Sq)
1 Combined groups 8 7 at level 1.4976E-05
2 Combined groups 8 6 at level 1.5623E-05
3 Combined groups 8 5 at level 2.5336E-04
4 Combined groups 8 4 at level 2.0625E-03
5 Combined groups 3 2 at level 2.3563E-03
6 Combined groups 10 9 at level 2.7781E-03
7 Combined groups 8 2 at level 3.7447E-03
8 Combined groups 10 2 at level 6.1073E-03
9 Combined groups 10 1 at level 8.6384E-03
************************************************************
clustering pass 123456789
No.-samples:
=========================
1 2007 ........|
2 2008 ....|.|||
3 2009 ....|.|||
4 2010 ...|..|||
5 2011 ..||..|||
6 2012 .|||..|||
7 2013 ||||..|||
8 2014 ||||..|||
9 2015 .....|.||
10 2016 .....|.||
************************************************************
V hlavičce soubor obsahuje informace o použité metodě, následují údaje o postupu shlukování a konečně jsou doplněny pseudografem znázorňujícím postup shlukování na jednotlivých hladinách.
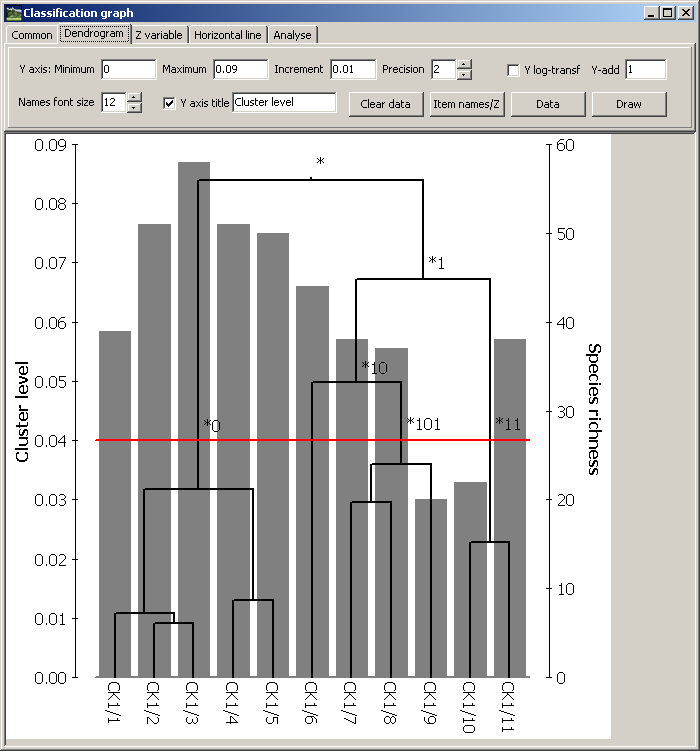
Dendrogramy (klasifikační grafy) lze vytvořit v samostatném okně vyvolaném příkazem menu Operace > Klasifikační graf.
Panel v horní části okna obsahuje záložky, v nichž je soustředěno ovládání konstrukce dendrogramů a nastavení vlastností výsledných grafů.
Záložka obsahuje prvky pro základní nastavení grafu a tlačítka pro jeho následné uložení a kopírování
Velikost grafu je určována v centimetrech. Současně je podstatné učení hustoty vzorkování bitmapy v pixelech na palec (DPI).

Pen vidth (pixels) - základní tloušťka čáry
Tlačítko Paper pro určení barvy papíru (podkladové barvy grafu)
Tlačítko Color slouží pro určení základní barvy pro kreslení dendrogramu
Text ident - odsazení textu v pixelech
Mark size - velikost značky na ose v pixelech
Check-box Graph title - zobrazování volitelného nadpisu grafu
(Graph title) Font size - velikost fontu pro nadpis grafu
Tlačítko 123Abc.. pro výběr základního fontu
Font size - velikost fontu pro popis vertikálních os
Tlačítko Copy zkopíruje vytvořený graf do schránky jako bitmapu.
Tlačítko Save umožní uložení grafu do souboru podle vybraného formátu (BMP, JPEG nebo TIFF)
Záložka slouží k vlastní konstrukci dendrogramu. Základní je nastavení osy pro znázornění shlukovacích hladin (Y axis). Hodnoty je možno rovněž logaritmicky transformovat dle výrazu
y' = log10(y+a)
kde a je zvolená konstanta (volíme a>0 v případech, kdy minimální distance mezi vzorky je nulová nebo blízká nule). Transformace bude uplatněna v případě, že je zaškrtnuta volba Y log-transf.

Name font size - velikost fontu užitého pro popis objektů.
Tlačítko Clear data - vymaže zobrazený graf, načtená data klasifikovaných objektů a údaje o shlukování.
Tlačítko Item names/Z - zobrazí dialog pro načtení a editaci jmen objektů a hodnot doplňkové proměnné Z. Data lze přímo editovat, načíst z otevřeného souboru snímků, načíst z textového souboru, vložit ze schránky Windows nebo jako příslušné hodnoty užít pořadová číslo objektů.
Tlačítko Data - slouží k načtení výsledků klasifikace, zpravidla výstupů z programů Cluster nebo HSCA, případně z libovolného textového souboru, který obsahuje podobné výsledky (například výsledky programu PC-ORD). Pokud používáme soubor *.out, pak je potřeba po otevření tohoto souboru v dialogovém okně pro načtení dat vymazat všechny řádky mimo ty, které obsahují vlastní informace o jednotlivých shlukovacích hladinách. Ve výše uvedeném příkladu se jedná tedy pouze o import řádků označených žlutě.
Tlačítko Draw - vykreslí graf podle stávajícího nastavení.
Ta obsahuje nastavení pro využití doplňkové (Z) proměnné. Může se jednat o libovolnou numerickou proměnnou, která je načítána společně se jmény jednotlivých vzorků. První řádek nastavení slouží k definování rozmezí zobrazované osy a intervalu mezi značkami.

Check-box Z-sort: pokud je pole zaškrtnuto, budou prvky v každém shluku seřazeny ve vzrůstajícím pořadí podle hodnoty proměnné Z (podle průměrů hodnot odpovídajících jednotlivým shlukovaným objektům).
Check-box Z-bar draw: spolu s dendrogramem bude vykreslen i sloupcový graf hodnot proměnné Z pro jednotlivé objekty.
Axis title - popis osy.
Brush - typ výplně vykreslovaných sloupců.
Color - barva vykreslovaných sloupců.
Záložka slouží k vložení horizontální linie určené pro vizuální odlišení významných shluků v dendrogramu.

Line width - šířka vkládané horizontální čáry v pixelech.
Tlačítko Color - barva čáry.
Editační pole Y - hodnota shlukové hladiny, která má být vkládanou čárou zobrazena.
Tlačítko Line draw - vložení čáry.
Tlačítko Classification groups vloží k uzlům klasifikačního grafu jejich označení.
Tlačítko Clear node texts vymaže všechny texty u uzlů klasifikačního grafu.

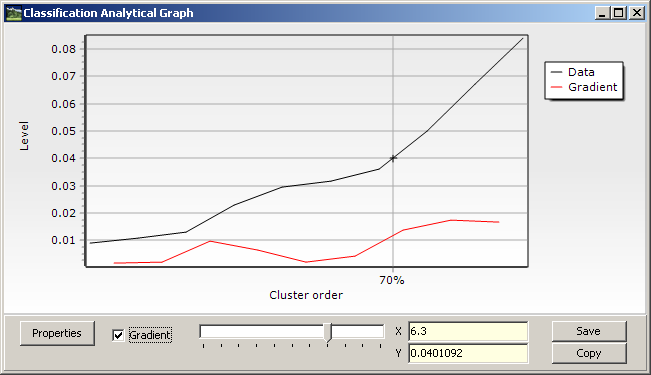
Tlačítko Order-level graph umožní vykreslit graf závislosti shlukové hladiny na pořadí shlukování. Takový graf slouží k odhadu hladiny, která je významná pro oddělení shluků, které lze smysluplně interpretovat. Na takové hladině je vhodné vložit do dendrogramu horizontální linii.
Tlačítko ANOVA for Z-variable umožňuje testovat signifikantnost rozdílů hodnot proměnné Z mezi identifikovanými shluky v průběhu shlukování. K tomu je využit Monte Carlo permutační test založený na kritériu počítanému shodně, jako F-test v rámci běžné jednofaktorové analýzy rozptylu (ANOVA). Významnost hodnot F je vyhodnocena Mote Carlo testováním s použitím předdefinovaného počtu iterací (běžně je dostačujících 1000 iterací). Významné jsou ty hodnoty F, které jsou vyšší, než odpovídající kritická hodnota (CV) při předem zvolené hladině významnosti (standardně 95%). Výsledky jsou zobrazovány v grafu, kde na horizontální ose je pořadí shlukování (od nejvyšší hladiny) a na vertikální ose je vynesena testovaná hodnota F spolu s kritickou hodnotou, případně odpovídající pravděpodobnost P. Testování je nezávislé na typu rozdělení hodnot Z. Testování je možno provést, pokud je shlukováno minimálně 10 objektů.
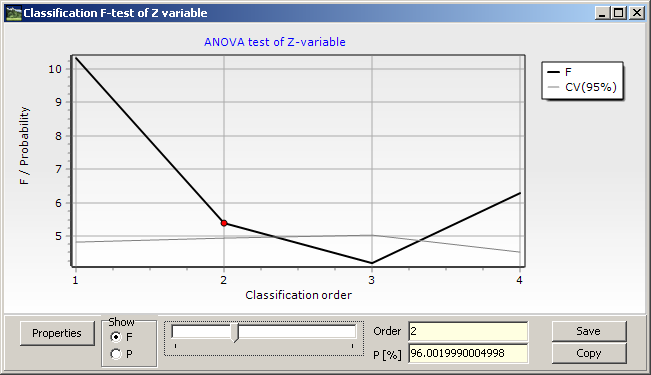
Vlastnosti obou předcházejících grafů je možné měnit pomocí dialogového okna, které se zobrazí pomocí tlačítka Properties. Grafy je možno uložit do souboru tlačítkem Save nebo zkopírovat tlačítkem Copy přes schránku Windows do jiné aplikace.
Kliknutím myší na libovolný uzel dendrogramu zobrazíme menu s položkami
Switch nodes - obrácení pořadí podřazených uzlů.
Node text - přiřazení nebo editace textu daného uzlu.
Node color - změna barvy uzlu.
Text equal to Z - u uzlu bude vypsána průměrná hodnota proměnné Z.
Dendrogram může být vykreslen samostatně nebo v kombinaci se sloupcovým grafem znázorňujícím libovolnou proměnnou, jak je tomu v následujícím příkladu, kde daty jsou fytocenologické snímky jedné studijní plochy, které byly získávány každým rokem během období 2007 až 2016. Protože se jedná o sekvenčně uspořádané vzorky, byla použita metoda HSCA/Sq. Během sukcese společenstva se výrazně mění jeho celková diversita. Data pro tento dendrogram jsou uvedena jako příklad souboru *.out výše.
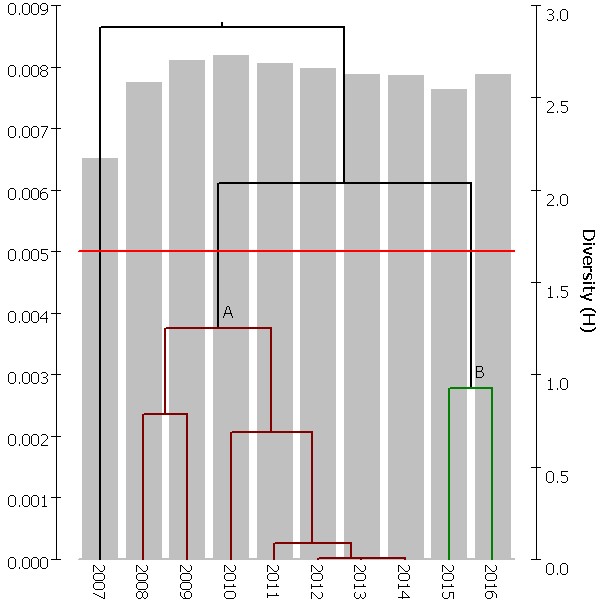
Na červenou linií zvýrazněné hladině 0,005 byly rozlišeny shluky A a B (jejich popisky byly dodány po kliknutí myší na centrální bod uzlu příslušného shluku, které vyvolá poup menu vázající se k tomuto shluku), které jsou rozlišeny též barevně.
Matějka K. (1993): Hierarchical semi-cluster analysis (HSCA): a new method of gradient analysis. - Ekológia Bratislava, 12: 131-152.
Matějka K. (2017): Multivariate analysis for assessment of the tree populations based on dendrometric data with an example of similarity among Norway spruce subpopulations. - Journal of Forest Science, 63: 449-456.
McCune B., Grace J.B. (2002): Analysis of ecological communities. - MjM Software Design, Gleneden Beach, Oregon.
McQuitty (1966): Similarity analysis by reciprocal pairs for discrete and continuous data. - Educational and Psychological Measurement, 26: 825.
Ward J.H. (1963): Hierarchical grouping to optimize an objective function. - Journal of the American Statistical Association, 58(301): 236-244.